 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Literal Translation: Evaluating Cultural Effectiveness in Social Media UGC
May 25, 2026Social media platforms enable large-scale cross-lingual communication, but translating user-generated content (UGC) remains challenging due to its informal style, cultural references, and interaction-based expressions. While recent LLMs have improved translation quality, existing benchmarks and metrics often fail to capture whether translations convey intended meaning and cultural resonance in real-world settings. In this work, we introduce CULTURE-MT, a benchmark for social media translation that focuses on both CULtural Transmission and UGC-specific emotion REsonance. CULTURE-MT consists of 1,002 UGC notes across 14 domains, categorized into four types based on culture-loaded symbols and linguistic style features. We also construct UGC-oriented training data to fine-tune Qwen3-8B and Qwen3-32B as baselines. We propose cultural effectiveness as a new evaluation criterion, focusing on expression accuracy and cultural adaptability. Testing 15 models, including the baselines, we find that traditional metrics fail to capture cultural effectiveness. We also observe that cultural effectiveness on base LLMs correlates with model size. Our work provides a comprehensive evaluation system for UGC translation models and will offer an open evaluation platform to advance research in this area. We release the CULTURE-MT benchmark and provide an online leaderboard where submitted translation results can be evaluated by our trained JUDGER.
Language as a Latent Variable for Reasoning Optimization
Apr 23, 2026As LLMs reduce English-centric bias, a surprising trend emerges: non-English responses sometimes outperform English on reasoning tasks. We hypothesize that language functions as a latent variable that structurally modulates the model's internal inference pathways, rather than merely serving as an output medium. To test this, we conducted a Polyglot Thinking Experiment, in which models were prompted to solve identical problems under language-constrained and language-unconstrained conditions. Results show that non-English responses often achieve higher accuracy, and the best performance frequently occur when language is unconstrained, suggesting that multilinguality broadens the model's latent reasoning space. Based on this insight, we propose polyGRPO (Polyglot Group Relative Policy Optimization), an RL framework that treats language variation as an implicit exploration signal. It generates polyglot preference data online under language-constrained and unconstrained conditions, optimizing the policy with respect to both answer accuracy and reasoning structure. Trained on only 18.1K multilingual math problems without chain-of-thought annotations, polyGRPO improves the base model (Qwen2.5-7B-Instruct) by 6.72% absolute accuracy on four English reasoning testset and 6.89% in their multilingual benchmark. Remarkably, it is the only method that surpasses the base LLM on English commonsense reasoning task (4.9%), despite being trained solely on math data-highlighting its strong cross-task generalization. Further analysis reveals that treating language as a latent variable expands the model's latent reasoning space, yielding consistent and generalizable improvements in reasoning performance.
Pause or Fabricate? Training Language Models for Grounded Reasoning
Apr 21, 2026Large language models have achieved remarkable progress on complex reasoning tasks. However, they often implicitly fabricate information when inputs are incomplete, producing confident but unreliable conclusions -- a failure mode we term ungrounded reasoning. We argue that this issue arises not from insufficient reasoning capability, but from the lack of inferential boundary awareness -- the ability to recognize when the necessary premises for valid inference are missing. To address this issue, we propose Grounded Reasoning via Interactive Reinforcement Learning (GRIL), a multi-turn reinforcement learning framework for grounded reasoning under incomplete information. GRIL decomposes the reasoning process into two stages: clarify and pause, which identifies whether the available information is sufficient, and grounded reasoning, which performs task solving once the necessary premises are established. We design stage-specific rewards to penalize hallucinations, enabling models to detect gaps, stop proactively, and resume reasoning after clarification. Experiments on GSM8K-Insufficient and MetaMATH-Insufficient show that GRIL significantly improves premise detection (up to 45%), leading to a 30% increase in task success while reducing average response length by over 20%. Additional analyses confirm robustness to noisy user responses and generalization to out-of-distribution tasks.
Enhancing LLM Language Adaption through Cross-lingual In-Context Pre-training
Apr 29, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite English-dominated pre-training, attributed to cross-lingual mechanisms during pre-training. Existing methods for enhancing cross-lingual transfer remain constrained by parallel resources, suffering from limited linguistic and domain coverage. We propose Cross-lingual In-context Pre-training (CrossIC-PT), a simple and scalable approach that enhances cross-lingual transfer by leveraging semantically related bilingual texts via simple next-word prediction. We construct CrossIC-PT samples by interleaving semantic-related bilingual Wikipedia documents into a single context window. To access window size constraints, we implement a systematic segmentation policy to split long bilingual document pairs into chunks while adjusting the sliding window mechanism to preserve contextual coherence. We further extend data availability through a semantic retrieval framework to construct CrossIC-PT samples from web-crawled corpus. Experimental results demonstrate that CrossIC-PT improves multilingual performance on three models (Llama-3.1-8B, Qwen2.5-7B, and Qwen2.5-1.5B) across six target languages, yielding performance gains of 3.79%, 3.99%, and 1.95%, respectively, with additional improvements after data augmentation.
AskToAct: Enhancing LLMs Tool Use via Self-Correcting Clarification
Mar 03, 2025



Large language models (LLMs) have demonstrated remarkable capabilities in tool learning. In real-world scenarios, user queries are often ambiguous and incomplete, requiring effective clarification. However, existing interactive clarification approaches face two critical limitations: reliance on manually constructed datasets and lack of error correction mechanisms during multi-turn clarification. We present AskToAct, which addresses these challenges by exploiting the structural mapping between queries and their tool invocation solutions. Our key insight is that tool parameters naturally represent explicit user intents. By systematically removing key parameters from queries while retaining them as ground truth, we enable automated construction of high-quality training data. We further enhance model robustness by fine-tuning on error-correction augmented data using selective masking mechanism, enabling dynamic error detection during clarification interactions. Comprehensive experiments demonstrate that AskToAct significantly outperforms existing approaches, achieving above 79% accuracy in recovering critical unspecified intents and enhancing clarification efficiency by an average of 48.34% while maintaining high accuracy in tool invocation. Our framework exhibits robust performance across varying complexity levels and successfully generalizes to entirely unseen APIs without additional training, achieving performance comparable to GPT-4 with substantially fewer computational resources.
TimeToM: Temporal Space is the Key to Unlocking the Door of Large Language Models' Theory-of-Mind
Jul 01, 2024Theory of Mind (ToM)-the cognitive ability to reason about mental states of ourselves and others, is the foundation of social interaction. Although ToM comes naturally to humans, it poses a significant challenge to even the most advanced Large Language Models (LLMs). Due to the complex logical chains in ToM reasoning, especially in higher-order ToM questions, simply utilizing reasoning methods like Chain of Thought (CoT) will not improve the ToM capabilities of LLMs. We present TimeToM, which constructs a temporal space and uses it as the foundation to improve the ToM capabilities of LLMs in multiple scenarios. Specifically, within the temporal space, we construct Temporal Belief State Chain (TBSC) for each character and inspired by the cognition perspective of the social world model, we divide TBSC into self-world beliefs and social world beliefs, aligning with first-order ToM (first-order beliefs) and higher-order ToM (higher-order beliefs) questions, respectively. Moreover, we design a novel tool-belief solver that, by considering belief communication between characters in temporal space, can transform a character's higher-order beliefs into another character's first-order beliefs under belief communication period. Experimental results indicate that TimeToM can dramatically improve the reasoning performance of LLMs on ToM questions while taking a big step towards coherent and robust ToM reasoning.
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Jan 04, 2024



The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.
Modeling Global Semantics for Question Answering over Knowledge Bases
Jan 05, 2021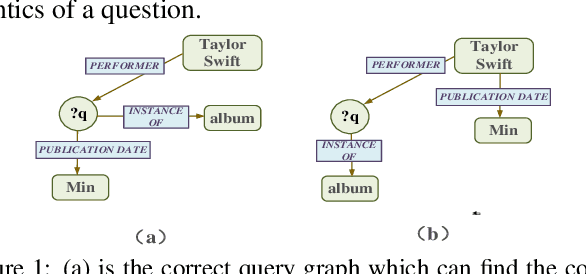
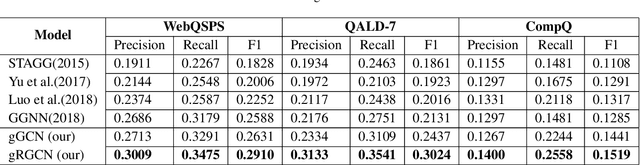
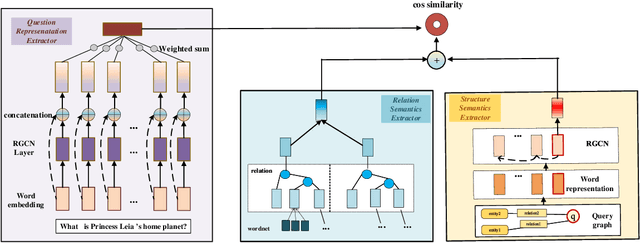
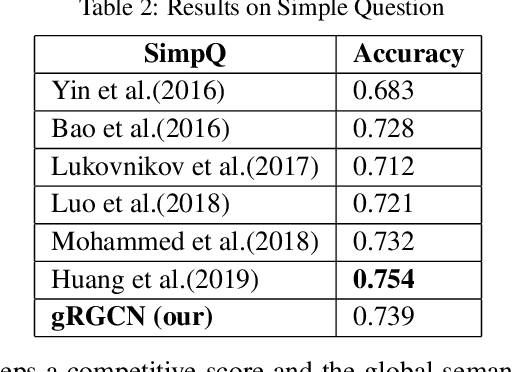
Semantic parsing, as an important approach to question answering over knowledge bases (KBQA), transforms a question into the complete query graph for further generating the correct logical query. Existing semantic parsing approaches mainly focus on relations matching with paying less attention to the underlying internal structure of questions (e.g., the dependencies and relations between all entities in a question) to select the query graph. In this paper, we present a relational graph convolutional network (RGCN)-based model gRGCN for semantic parsing in KBQA. gRGCN extracts the global semantics of questions and their corresponding query graphs, including structure semantics via RGCN and relational semantics (label representation of relations between entities) via a hierarchical relation attention mechanism. Experiments evaluated on benchmarks show that our model outperforms off-the-shelf models.